




Файл robots.txt является важным инструментом для управления индексацией веб-сайта поисковыми системами. Он позволяет вам указать поисковым роботам, какие страницы следует сканировать, а какие игнорировать. Рассмотрим подробнее, как правильно создать и использовать файл robots.txt, чтобы закрыть сайт от индексации теми страницами, которые вы не хотите видеть в поисковых результатах.
Что такое файл robots.txt
Файл robots.txt представляет собой текстовый файл, который располагается на сервере в корневом каталоге веб-сайта и содержит инструкции для поисковых роботов о том, как индексировать содержимое сайта. Этот файл используется для контроля доступа к различным разделам сайта и регулирования индексации его страниц поисковыми системами.Как работает файл robots.txt:
-
Идентификация поисковых роботов: Когда поисковый робот (или "паук") посещает ваш сайт, он сначала проверяет наличие файла robots.txt в корневом каталоге. Если такой файл существует, поисковый робот анализирует его содержимое, чтобы определить, какие страницы сайта следует индексировать, а какие нет.
-
Правила и директивы: Файл robots.txt состоит из набора правил, каждое из которых определяет, какой поисковый робот может сканировать какие страницы. Основные директивы в файле robots.txt включают User-agent, Disallow и Allow.
-
User-agent: Эта директива указывает на конкретного поискового робота или группу роботов, к которым применяется правило.
-
Disallow: Директива Disallow указывает на страницы или каталоги сайта, которые поисковый робот не должен индексировать. Если поисковый робот видит указание Disallow для определенной страницы, он пропускает её при сканировании.
-
Allow: Директива Allow позволяет определить конкретные страницы или каталоги, которые все же должны быть индексированы поисковым роботом, даже если они заблокированы правилом Disallow.
Зачем нужен файл robots.txt:
-
Управление индексацией: Файл robots.txt дает вам возможность управлять тем, какие части вашего сайта будут индексироваться поисковыми системами, а какие нет. Это особенно полезно, если на вашем сайте есть страницы с дублирующимся или временным контентом, которые не должны отображаться в результатах поиска.
-
Защита конфиденциальной информации: Вы можете использовать файл robots.txt, чтобы запретить индексацию страниц с конфиденциальной информацией или административными разделами вашего сайта, чтобы предотвратить их случайное открытие в поисковых результатах.
-
Оптимизация скорости индексации: Используя правильные инструкции в файле robots.txt, вы можете направить поисковых роботов сканировать наиболее важные страницы вашего сайта с более высокой частотой, что может улучшить скорость индексации и обновления содержимого в поисковых системах.
Структура и синтаксис файла robots.txt
Файл robots.txt имеет простую структуру и используется для предоставления инструкций поисковым роботам о том, как индексировать содержимое сайта. Рассмотрим более подробно его структуру и основные элементы:
1. Корневой каталог:
Файл robots.txt должен располагаться в корневом каталоге вашего сайта. Это обеспечивает доступность файла для поисковых систем и позволяет им легко находить и применять инструкции.
2. Правила:
Файл robots.txt состоит из набора правил, каждое из которых определяет инструкции для конкретного поискового робота. Каждое правило начинается с идентификатора User-agent, за которым следуют директивы Disallow или Allow.
3. User-agent:
Идентификатор User-agent определяет поискового робота, к которому применяются правила. Можно указать конкретного робота или использовать символ звездочки (*) для указания всех роботов.
4. Disallow:
Директива Disallow указывает на страницы, которые не должны быть индексированы поисковыми системами. Запрет доступа к определенным страницам или каталогам происходит с помощью указания пути к ним относительно корневого каталога сайта.
5. Allow:
Директива Allow указывает на страницы, которые поисковые системы могут индексировать, несмотря на общий запрет на индексацию. Это может быть полезно, если вы хотите разрешить индексацию определенных страниц, но запретить доступ к другим.
Пример:
Ниже приведен пример простого файла robots.txt с одним правилом для всех поисковых роботов:
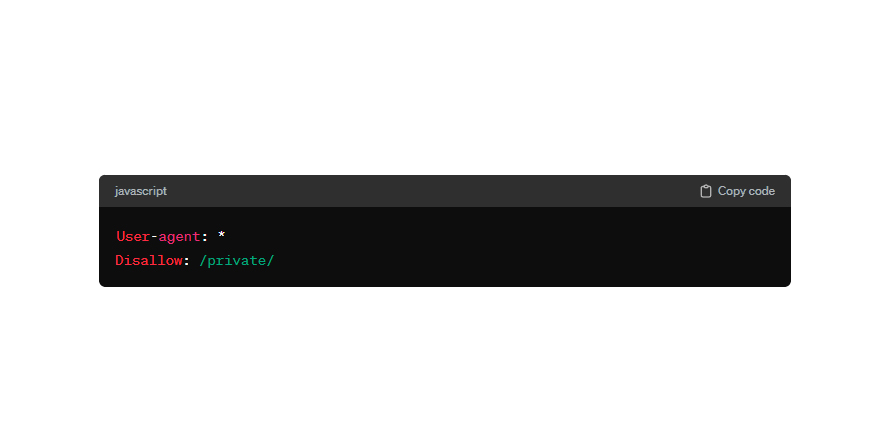
Этот файл запрещает поисковым роботам индексировать все страницы, находящиеся в каталоге "/private/".
Как создать файл robots.txt
1. Шаги по созданию и настройке файла robots.txt:
-
Идентификация запретов и разрешений: Прежде всего, определите, какие страницы или разделы вашего сайта вы хотите исключить из индексации поисковыми системами и какие можно оставить открытыми для сканирования.
-
Создание правил: Используйте текстовый редактор, такой как Notepad или Sublime Text, чтобы создать новый файл с именем "robots.txt". Для каждого типа страницы или раздела укажите соответствующие правила в файле.
-
Формат правил: Каждое правило начинается с идентификатора User-agent, за которым следует директива Disallow или Allow. Например:

2. Рекомендации по размещению файла на сервере:
-
Правильное расположение: Разместите файл robots.txt в корневом каталоге вашего веб-сервера. Это позволит поисковым роботам легко найти и прочитать файл при сканировании вашего сайта.
-
Проверка доступности: Убедитесь, что файл доступен для чтения поисковыми системами. Проверьте права доступа к файлу и наличие ошибок в путях к файлу.
3. Инструменты для проверки правильности синтаксиса и функционирования файла robots.txt:
-
Проверка синтаксиса: Используйте онлайн-инструменты, такие как Google Robots.txt Tester или Yandex Robots.txt Validator, для проверки синтаксиса и правильности написания правил в файле robots.txt.
-
Проверка доступности: Воспользуйтесь функцией "Просмотр файла robots.txt" в Google Search Console или Яндекс.Вебмастер для проверки того, как поисковые системы видят и интерпретируют ваш файл robots.txt.
-
Проверка индексации: После размещения и настройки файла robots.txt, проверьте его эффективность с помощью инструментов аналитики, таких как Google Analytics или Яндекс.Метрика, чтобы убедиться, что запреты и разрешения применяются корректно.
Основные директивы и использование
Директива "User-agent":
Директива "User-agent" позволяет указать поисковым роботам правила индексации для конкретных агентов. Это означает, что вы можете настроить индексацию для различных поисковых систем или даже для отдельных роботов. Например, вы можете разрешить индексацию всем роботам или только конкретному роботу Яндекса или Google. Пример использования:

В этом примере мы указываем, что все роботы должны игнорировать страницы, находящиеся в разделе "/private/".
Директива "Disallow":
Директива "Disallow" используется для запрета доступа к определенным страницам или разделам сайта. Это полезно, если вы не хотите, чтобы поисковые системы индексировали часть вашего контента. Пример использования:

В этом примере мы указываем, что робот Googlebot не должен индексировать страницы в разделе "/admin/".
Другие полезные директивы:
Allow: Директива "Allow" используется для разрешения доступа к определенным страницам или разделам сайта, если они были запрещены с помощью директивы "Disallow".
Пример:
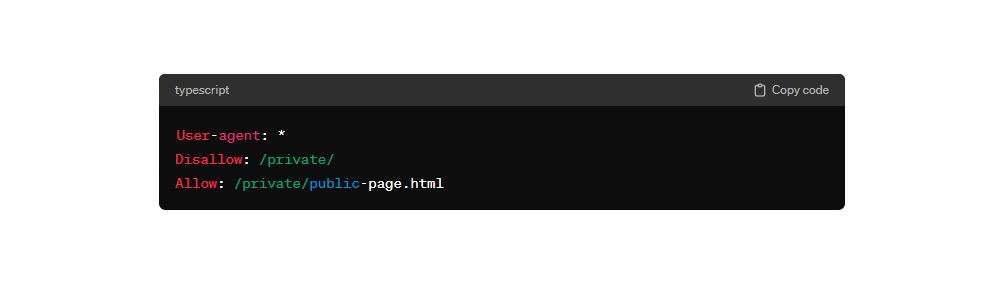
Crawl-delay: Директива "Crawl-delay" позволяет задать задержку между запросами робота к вашему серверу. Это может быть полезно, чтобы снизить нагрузку на сервер в случае большого количества запросов от поисковых систем.
Пример:

Sitemap: Директива "Sitemap" указывает путь к файлу XML-карты сайта. Это помогает поисковым системам быстрее и эффективнее индексировать ваш сайт.
Пример:
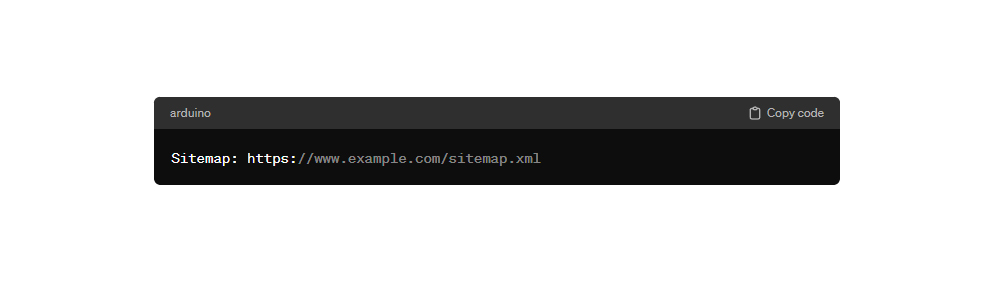
Это основные директивы файла robots.txt, которые используются для управления индексацией сайта поисковыми системами. Правильное использование этих директив поможет оптимизировать индексацию и улучшить видимость вашего сайта в поисковых результатах.
Особые случаи и советы
Управление индексацией различных типов контента:
При создании файла robots.txt важно учитывать различные типы контента на вашем сайте, такие как страницы, изображения, видео и другие. Для каждого типа контента можно настроить свои правила индексации, чтобы оптимизировать видимость вашего контента в поисковых системах.
Предотвращение индексации конфиденциальной информации и временных страниц:
Для защиты конфиденциальной информации и временных страниц от индексации поисковыми системами следует использовать директиву Disallow в файле robots.txt. Это позволит исключить указанные страницы из индекса поисковых систем и предотвратить их отображение в поисковых результатах.
Советы по обновлению и поддержанию файла robots.txt:
1. Регулярное обновление: При внесении изменений на вашем сайте, таких как добавление новых страниц или изменение структуры URL, необходимо обновлять файл robots.txt соответствующим образом.
2. Проверка и тестирование: После внесения изменений в файл robots.txt рекомендуется проверить его правильность и эффективность с помощью различных инструментов и методов тестирования.
3. Документация и комментарии: Для удобства поддержания и понимания файл robots.txt рекомендуется добавлять комментарии к правилам, объясняющие их назначение и применение. Также важно вести документацию об изменениях, внесенных в файл.
4. Отслеживание ошибок: Регулярно отслеживайте возможные ошибки или проблемы с индексацией, связанные с файлом robots.txt, и оперативно вносите необходимые исправления.
Как проверить правильность и эффективность файла robots.txt
Инструменты и методы для тестирования и анализа файла robots.txt:
Google Search Console:
-
Google Search Console предоставляет инструменты для анализа и проверки файла robots.txt.
-
После добавления сайта в Google Search Console вы можете проверить, как Googlebot воспринимает ваш файл robots.txt и обнаружить возможные проблемы.
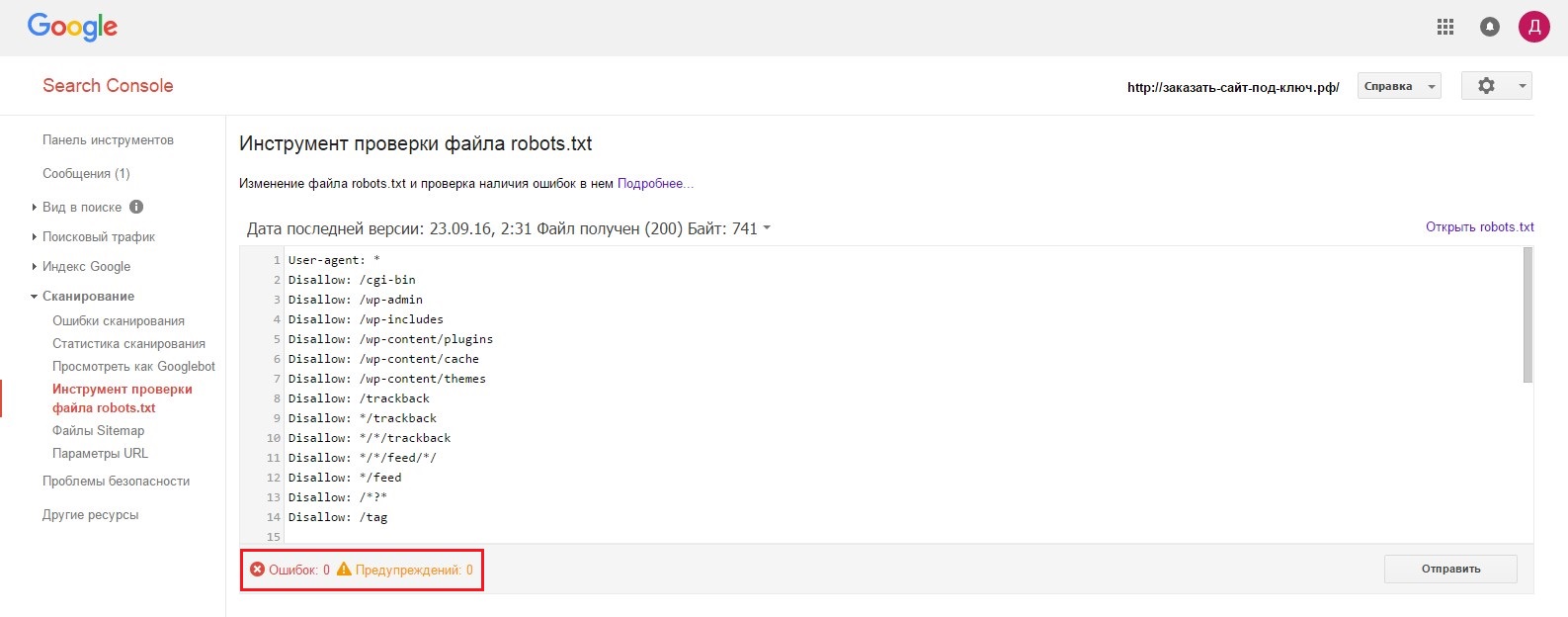
Robots.txt Tester в Google Search Console:
-
Этот инструмент в Google Search Console позволяет проверить файл robots.txt на предмет ошибок и неправильных настроек.
-
Вы можете вручную проверить доступность страниц для поисковых роботов и убедиться, что они настроены корректно.
Онлайн сервисы для проверки файлов robots.txt:
-
Существуют различные онлайн сервисы, которые могут провести проверку файла robots.txt на наличие ошибок и несоответствий с рекомендациями поисковых систем.
-
Некоторые из них предоставляют детальные отчеты о структуре и содержании файла, что помогает выявить потенциальные проблемы.
Как убедиться, что запреты и разрешения применяются корректно:
1. Проверьте доступность страниц:
Посетите страницы, указанные в файле, чтобы убедиться, что они доступны.
2. Анализ журналов:
Проверьте, какие страницы были заблокированы или разрешены для индексации.
3. Проверка индексации:
Используйте поисковые запросы, чтобы убедиться, что страницы отображаются корректно.
Заключение
Файл robots.txt - это мощный инструмент для управления индексацией вашего сайта поисковыми системами. Правильное создание и использование этого файла позволяет контролировать доступ к страницам сайта для поисковых роботов и улучшить SEO-показатели вашего веб-ресурса. Надеемся, что данная статья помогла вам лучше понять, как закрыть сайт от индексации с помощью файла robots.txt, и применить полученные знания на практике. Помните, что регулярное обновление и тестирование файла robots.txt позволит вам сохранить контроль над индексацией вашего сайта и повысить его видимость в поисковых системах.


